История технических способов кодирования информации. Древние способы кодирования информации
"Кодирование информации" (из истории) - информатика, мероприятия  Введение Человек живет в мире информации и воспринимает окружающий мир с помощью органов чувств. Чтобы правильно воспринимать все происходящее в мире, он запоминает полученные сведения, т.е. хранит информацию, человек принимает решения, т.е. обрабатывает информацию, а при общении с другими людьми – передает и принимает информацию. Кодирование информации необычайно разнообразно. Дорожные знаки, ноты, кодирующие музыку на бумаге, обозначения на географических картах, химические формулы – это маленькая часть кодирования различной информации, которую мы получаем почти каждый день. Мы с моей сестрой Алиной иногда пишем друг другу сообщения и оставляем в различных местах. И чтоб было интереснее, решили придумать свой алфавит (прилагается). Уже потом, я узнала, что с помощью придуманных нами картинок мы кодировали наши письма. Мне стало интересно, а кто придумал кодирование, где использовали кодирование, где применяют сейчас. Еще было интересно – что знают мои одноклассники о кодировании. Я провела анкетирование среди своих одноклассников. Что вы знаете о кодировании? Встречались ли вы с кодами в жизни? Как вы думаете, зачем люди кодируют информацию? Что нужно знать, чтоб кодировать информацию?
Наиболее частыми ответами на первый вопрос были: - запись слов так, чтоб никто не понял - вставка рисунков вместо слов - шифрование текста - запись слов на непонятном языке -не знаю Наиболее частыми ответами на второй вопрос были: - в кино радисты передают шифровки - иностранные языки - на этикетках товаров цифры вместо слов - не встречались Наиболее частыми ответами на третий вопрос были: - что бы скрыть от других - записывают короче длинные предложения - удобно передавать информацию - спрятать от любопытных людей - просто так Наиболее частыми ответами на четвертый вопрос были: - знаки для кодирования - придумать картинки - таблицу, чтобы закодировать и раскодировать информацию - не знаю Так как в ответах на каждый вопрос были такие, что одноклассники не знают ответ, я решила найти различную информацию по этому вопросу и довести ее до них. Возникновение кодирования. Кoды появились еще в глубокой древноcти в виде криптограмм (по-гречески — тайнописи), когда ими пользoвались для засекречивaния важного сообщения от тех, кому оно не было предназначенo.  Уже знаменитый грeческий истoрик Геродот (V век до н. э.) приводил примеры писем, понятных лишь для одного адресата. Спартанцы имели специальный механический прибор, при помощи которого важные сoобщения можно было писать осoбым способом, oбеспечивающим сохранение тайны. В средние века и эпоху Вoзрождения над изобретением тaйных шифрoв трудились многие выдающиеся люди, в их числе философ Фрэнсис Бэкон, крупные мaтематики Франсуa Виет, Джероламо Кардано.С течением времени начали появляться по-настоящему сложные шифры. Один из них, употребляемый и поныне, связан с именем ученого аббата из Вюрцбурга Тритемиуса, которого к занятиям криптографией толкало, не только монастырское уединение, но и потребность сохранять от огласки некоторые духoвные тайны. Различные хитроумные приемы кодирования применяли шифровальщики при папском дворе и дворах европейских королей. Вместе с искусством шифрования развивалось и искусство дешифровки, или, как говорят, криптоанализа. Еще один дрeвнейший шифр - код Цeзаря. При шифровании каждый симвoл заменяется другим, отстоящим от него в алфавите на фиксированное число позиций. Про шифр Цезаря можно сказать, что это шифр подстановки— шифр простой замены. Шифр назван в честь римского императора Гая Юлия Цезаря, использовавшего его для секретной переписки. Естественным рaзвитием шифра Цезаря стал шифр Виженера. На пример: шифрование с использованием ключа k = 3. Буква «С» как бы сдвигается на три буквы впeред и становится буквой «Ф». Твердый знак, перемещённый на три буквы вперед, становится буквой «э», и так далее: | Оригинальный текст: | Шифрованный текст: | | Съешь ещё этих булок. | Фэзыя зьи ахлш дцосн. |
Метод кодирования Морзе был изобретён для передачи сообщений по телеграфным линиям. Eго изобретатель, американец Сэмюэл Финли Бриз Морзе (1791-1872), был также известным художником. В своё время он изучал рисование в Лондоне и там узнал об исследованиях электромагнетизма, проводимых британскими учёными. Возвращаясь по морю в США в 1832-м году, он задумал создать свою собственную систему телеграфа. Именно с этой системы началось движение в сторону того мира электронных сетей, в котором мы сейчас живём, и именно за её разработку Морзе снискал славу "американского Леонардо да Винчи". Морзе изобрёл метод кодирования, который он использовал для посылки своего исторического сообщения, в 1838-м году. Метод кодирования Морзе напоминает двоичный код, используемый в современных компьютерах, тем, что он тоже базировался на двух возможных значениях - в случае метода кодирования Морзе, это были точка или тире (рис.1). Однако в отличие от современных методов кодирования, используемых для нумерации символов в современных компьютерах, комбинации точек и тире, используемые для представления символов в методе кодирования Морзе, были разной длины. Морзе использовал принцип, по которому наиболее часто употребляемым буквам ставились в соответствие наиболее короткие последовательности из точек и тире, что существенно сокращало длину сообщения. Например, наиболее часто используемой в английском языке букве "E" в методе кодирования Морзе соответствует одна точка; второй по частоте использования букве английского языка - "T" - одно тире.  рис.1 рис.1 Кoнец XIX-го века ознаменoвался изобретением ещё oдной системы для кодирoвания символов eстественных языков. Онa была создана в США для обработки данных, собираемых во время перeписей населения, молодым американским изобретателем Германoм Холлеритoм (1860-1929). После окончания Нью-Йоркской Колумбийской школы горного дела в 1879-м году, в 1880-м Холлерит устроился на работу в Бюро статистики при Министерстве внутренних дел США. Последствия этого, казалось бы, незначительного события сказывались впоследствии вплоть до 1970-х годов, "золотой эры" больших вычислительных машин. Герман Холлерит был ни кем иным, как изобретателем кода Холлерита, использовавшегося для записи алфавитно-цифровой информации на бумажных перфорированных картах. АЗБУКА БРАЙЛЯ — специальная азбука, созданная Л. Брайлем (1809—1852) для воспроизведения текста в изданиях для слепых (рис.2). Каждый знак в тексте печатают в виде комбинации одной — шести выпуклых точек, расположенных на площади прямоугольника. Чтение текста, основано на осязании рельефных точек и восприятии их комбинаций.  рис.2 рис.2  Код Трисиме (рис.3) является примером, так называемoго, равномерногo кода - такoго, в котором все кодовые кoмбинации содержат одинакoвое числo знaков - в данном случае три- знакам лaтинского алфавита ставятся в соответствие кoмбинации из трех знаков: 1,2,3: А 111 H 132 O 223 V 321 В 112 I 133 P 231 W 322 С 113 J 211 Q 232 X 323 В 121 K 212 R 233 Y 331 D 122 L 213 S 311 Z 332 F 123 M 221 T 312 . 333 G 131 N 222 U 313 рис.3 Для кодирования текстовой информации принят международный стандарт ASCII (American Standard Code for Information Interchange) (рис.4), в кодовой таблице которого занято 128 7-ми разрядных кодов для: символов латинского алфавита цифр знаков препинания математических символов Добавление 8-го разряда позволяет увеличить количество кодов таблицы ASCII до 255. Коды от 128 до 255 представляют собой расширение таблицы ASCII. Эти коды в таблице ASCII использованы для кодирования некоторых символов, отличающихся от латинского алфавита, и встречающихся в языках с письменностью, основанной на латинском алфавите, - немецком, французском, русском и др. Кроме этого, часть кодов использована для кодирования символов псевдографики, которые можно использовать, например, для оформления в тексте различных рамок и текстовых таблиц. В русском алфавите буква А имеет первое место, а буква Б - второе. У каждой буквы есть своя позиция. Буква Я имеет позицию номер 33. Мы можем считать, что алфавит - это таблица для кодирования букв. Стандарт ASCII -- это тоже как бы «алфавит», только компьютерный. Он тоже определяет номер каждого символа. Но символов больше, чем букв, потому что к ним относятся еще и цифры, и знаки препинания, и некоторые специальные символы. Самый первый символ стандарта ASCII - это ПРОБЕЛ. Он имеет код 32. За ним идут специальные символы и знаки препинания (коды с 33 по 47). Далее идут десять цифр (коды 48-57). Коды 58-64 используют некоторые математические символы и знаки препинания. Самое интересное начинается с кодов 65--90. Ими обозначают прописные английские буква от А до Z Коды 91--96 используются для специальных символов. Коды 97--122 -- строчные буквы английского алфавита. Коды 123-127 -- специальные символы. Рис.4 В относительно древние времена учёные люди очень любили публиковать различного рода послания в необычных кодировках. Самый яркий кодировочный пример — творчество Мишеля Нострадамуса. Популярность Мишеля Нострадамуса – знаменитого французского прорицателя – просто грандиозна. Уже несколько веков люди усердно изучают его катрены (четверостишия), пытаясь угадать тайны будущего. Нострадамус был не только прорицателем, но и врачом, алхимиком, астрономом. Это был человек с энциклопедическими познаниями. Его сборники предсказаний постоянно ставили в тупик многочисленных толкователей. И не только из-за туманных и многозначных выражений. В некоторых из них содержатся видимые противоречия и явные ошибки, которые вроде бы не мог допускать столь выдающийся человек. Одна из самых известных и загадочных центурий Нострадамуса – «Послание к Генриху». Оно адресовано королю Франции Генриху Второму и написано в 1558 году. Множество ошибок и неточностей наводило исследователей на мысль о скороспелости и недостаточной проработанности центурии. Однако Нострадамус писал это послание почти год, постоянно исправляя и выверяя текст. Вдобавок вряд ли Нострадамус решился преподнести королю сырое и неудачное произведение. А ошибочные цитаты из Библии вообще в те времена могли стоить обвинения в ереси. Поэтому очевидно: ошибки сделаны преднамеренно. Видимо в них кроется какой-то секретный код, который толкователи не смогли разгадать, хотя тщательнейшим образом проработали каждое слово. Многие полагают, что еще задолго до Кирилла и Мефодия (которых называют изобретателями славянской письменности), славяне имели свою оригинальную систему письма, - так называемую узелковую письменность. Знаки этой «письменности» не записывались, а передавались с помощью узелков, завязанных на нитях, которые заматывались в клубки-книги. В древности узелковая письменность была распространена довольно широко. Это подтверждают археологические находки. На многих предметах, поднятых из захоронений языческого времени, видны несимметричные изображения узлов, служившие не только для украшения (рис.5).  рис.5 Каждому узлу соответствовало свое слово. С помощью дополнительных узелков сообщали дополнительные сведения о нем, например его число, часть речи и пр. Часто в сочинениях христианского времени встречаются иллюстрации с изображениями сложных переплетений, вероятно, перерисованных с предметов языческой эпохи. Следы узелковой письменности можно найти и на стенах храмов, построенных в эпоху «двоеверия», когда христианские храмы украшались не только ликами святых, но и языческими узорами. Исследователи предприняли попытку расшифровать некоторые из этих знаков (рис.6).  Рис.6 Существующую сегодня на флоте русскую семафорную азбуку (рис.7) разработал в 1895 году вице-адмирал Степан Осипович Макаров. Русская семафорная азбука составлена в соответствии с русским алфавитом, включает 29 буквенных и 3 служебных знака. Она не содержит цифр и знаков препинания. Их передача производится по буквам, словами. Например, цифра «7» будет передана словом «семь», а знак «,» — словом «запятая». Каждой букве и условному знаку соответствует определенное положение рук с флажками. Семафорное сообщение состоит из слов, составленных из букв, изображаемых соответствующим положением флажков. Передача информации семафором производится сигнальщиками с помощью флажков, размер ткани которых составляет 30x35 см. Цвет ткани флажков зависит от времени суток: в тёмное время суток используются флажки с тканью светлого тона (желтый, белый), а в светлое время суток — с тканью тёмного тона (красный, чёрный). Средняя скорость передачи флажным семафором обученным сигнальщиком составляет 60-80 знаков в минуту.  рис.7 рис.7 Стенография – это скоростное письмо особыми знаками, настолько краткими, что ими можно записать живую речь. Стенография пришла к нам из древнейших времен. Еще в Древнем Египте скорописцы записывали речь фараонов. Широкое распространение стенография получила в Древней Греции. В 1883 г. в Акрополе была найдена мраморная плита, на которой были высечены стенографические знаки. По мнению ученых, эти записи были сделаны в 350 г. до н.э. Но общепризнанным днем рождения стенографии считается 5 декабря 63 года до н.э. Тогда в Древнем Риме возникла необходимость дословной записи устной речи. Автором древнеримской стенографии считается Тирон – секретарь знаменитого оратора Цицерона. В современном мире, несмотря на обилие средств механической фиксации слова (магнитофонов, диктофонов), владение навыками стенографии по-прежнему ценится. Мы записываем в среднем в пять раз медленнее, чем говорим. Стенография же ликвидирует этот разрыв. Она особенно полезна при конспектировании лекций, публичных выступлений, бесед, составлении докладов, подготовке статей и т. п.  рис.8 рис.8 Применение кодирования информации Персональные данные. В последнее время очень актуален вопрос о персональных данных. ИИН - Индивидуальный Идентификационный Номер, 12-значный цифровой код, который присваивается физическому лицу один раз и пожизненно. с 1 января 2012 года заменит РНН и СИК. Расшифровка ИИН : первые 6 разрядов - это дата рождения ггммдд, то есть 12 августа 1985 года в ИИНе будет 850812 7 разряд отвечает за век рождения и пол. Если цифра нечетная - пол мужской, четная - женский. 1,2 - девятнадцатый век, 3,4 - двадцатый, 5,6 - двадцать первый. 8-11 разряды - заполняет орган Юстиции. 12 разряд - контрольная цифра, которая расчитывается по определенному алгоритму. Штрих-коды. С развитием информационной техники, широким внедрением средств вычислительной техники во многие сферы деятельности все острее встает вопрос быстрого и надежного ввода информации. Ручной ввод кода изделия требуют больших затрат ручного труда, времени, часто приводит к ошибкам. В настоящее время ведутся большие работы по созданию автоматизированных систем обработки данных с применением машиночитаемых документов (МЧД), одной из разновидностей которых являются документы со штриховыми кодами. К машиночитаемым относятся товаросопроводительные документы, ярлыки и упаковки товаров, чековые книжки и пластиковые карточки для оплаты услуг, магнитные носители. В связи с этим появились термины “электронные ведомости”, “электронные деньги” и т. д. Штриховой код представляет собой чередование темных и светлых полос разной ширины (рис.9). В настоящее время штриховые коды широко используются не только при производстве и в торговле товарами, но и во многих отраслях промышленного производства. Товарный штриховой код присваивается продукции (товару) на этапе запуска его в производство. Штрих-коды получили широкое практическое применение почти во всех сферах деятельности человека: На удостоверении личности; На продуктах в магазинах «Метро», «Рубиком», «Гринвич»; Карты безопасности; Пройти в метро;
 рис.9 рис.9 Смайлики.    С появлением электронного общения, появилась необходимость передачи своих чувств через компьютер. В обычном тексте сделать это достаточно сложно, из-за чего и появились специфические знаки препинания (так называемые смайлики). Смайликами (от smile – улыбка) в Интернете называют значки, составленные из знаков препинания, букв и цифр, обозначающие какие-то эмоции. Смайлик – это лучший способ «закодировать» чувства и эмоции при виртуальном общении! Маленькие забавные рожицы, которые вставляются в текст, избавляют от необходимости писать излияния о ваших переживаниях. Без него невозможно обойтись ни в одной форме виртуального общения. Он крайне прост в употреблении, информативен и при всей своей простоте дает широкий простор воображению. Неудивительно, что его переняли sms-коммуникация, реклама, дизайн, обычная почта, при обмене записками на уроках. Смайлики настолько прочно вошли в нашу жизнь, что перекочевали из виртуального пространства в науки. Так в психологии, смайлики используют для обозначения типов темпераментов или отслеживают настроение человека. Заключение Множество кодов очень прочно вошло в нашу жизнь. Заинтересовавшись вопросами кодирования информации, я стала искать примеры художественных произведений, в которых говорилось о кодировании информации. Вот, что я нашла: Артур Конан Дойль “Пляшущие человечки”; Эдгар По “Золотой жук”; Жюль Верн “Путешествие к центру земли”; Дэн Браун “Код да Винчи”.
Получается, что вопросы кодирования интересовали не только ученых, но и писателей, которые включили сцены кодирования информации в свои произведения. Я не читала еще эти произведения, но, думаю, в ближайшее время их прочту. После поиска информации, меня очень заинтересовал вопрос о штрих-кодах. Думаю, я продолжу работу по изучению штрих-кодов на различных товарах. Нужно, чтобы люди (не только программисты-профессионалы, но и простые пользователи) имели понятие о кодировании информации и о возможных способах кодирования разных видов информации. Список использованной литературы Л.Л. Босова, УМК по информатике для 5-7 классов http://otherreferats.allbest.ru/programming/00029252_0.html http://xreferat.ru/33/2153-1-kodirovanie-informacii.html www.grandars.ru http://www.yoursmileys.ru/smileys.php Угринович Н.Д. Информатика и информационные технологии. Учебник для 10-11 классов / Н.Д.Угринович. – М.: БИНОМ. Лаборатория знаний, 2003. –
13 kopilkaurokov.ru Кодирование информации. Способы кодирования информации. ⇐ ПредыдущаяСтр 3 из 7Следующая ⇒В настоящее время во всех вычислительных машинах информация представляется с помощью электрических сигналов. При этом возможны две формы ее представления – в виде непрерывного сигнала (с помощью сходной величины – аналога) и в виде нескольких сигналов (с помощью набора напряжений, каждое из которых соответствует одной из цифр представляемой величины). Первая форма представления информации называется аналоговой, или непрерывной. Величины, представленные в такой форме, могут принимать принципиально любые значения в определенном диапазоне. Количество значений, которые может принимать такая величина, бесконечно велико. Отсюда названия – непрерывная величина и непрерывная информация. Слово непрерывность отчетливо выделяет основное свойство таких величин – отсутствие разрывов, промежутков между значениями, которые может принимать данная аналоговая величина. При использовании аналоговой формы для создания вычислительной машины потребуется меньшее число устройств (каждая величина представляется одним, а не несколькими сигналами), но эти устройства будут сложнее (они должны различать значительно большее число состояний сигнала). Непрерывная форма представления используется в аналоговых вычислительных машинах (АВМ). Эти машины предназначены в основном для решения задач, описываемых системами дифференциальных уравнений: исследования поведения подвижных объектов, моделирования процессов и систем, решения задач параметрической оптимизации и оптимального управления. Устройства для обработки непрерывных сигналов обладают более высоким быстродействием, они могут интегрировать сигнал, выполнять любое его функциональное преобразование и т. п. Однако из-за сложности технической реализации устройств выполнения логических операций с непрерывными сигналами, длительного хранения таких сигналов, их точного измерения АВМ не могут эффективно решать задачи, связанные с хранением и обработкой больших объемов информации. Вторая форма представления информации называется дискретной (цифровой). Такие величины, принимающие не все возможные, а лишь вполне определенные значения, называются дискретными (прерывистыми). В отличие от непрерывной величины, количество значений дискретной величины всегда будет конечным. Дискретная форма представления используется в цифровых электронно-вычислительных машинах (ЭВМ), которые легко решают задачи, связанные с хранением, обработкой и передачей больших объемов информации.
Для автоматизации работы ЭВМ с информацией, относящейся к различным типам, очень важно унифицировать их форму представления – для этого обычно используется прием кодирования. Кодирование – это представление сигнала в определенной форме, удобной или пригодной для последующего использования сигнала. Говоря строже, это правило, описывающее отображение одного набора знаков в другой набор знаков. Тогда отображаемый набор знаков называется исходным алфавитом, а набор знаков, который используется для отображения, – кодовым алфавитом, или алфавитом для кодирования. При этом кодированию подлежат как отдельные символы исходного алфавита, так и их комбинации. Аналогично для построения кода используются как отдельные символы кодового алфавита, так и их комбинации. Совокупность символов кодового алфавита, применяемых для кодирования одного символа (или одной комбинации символов) исходного алфавита, называется кодовой комбинацией, или, короче, кодом символа. При этом кодовая комбинация может содержать один символ кодового алфавита. Символ (или комбинация символов) исходного алфавита, которому соответствует кодовая комбинация, называется исходным символом. Совокупность кодовых комбинаций называется кодом. Взаимосвязь символов (или комбинаций символов, если кодируются не отдельные символы исходного алфавита) исходного алфавита с их кодовыми комбинациями составляет таблицу соответствия (или таблицу кодов).
В качестве примера можно привести систему записи математических выражений, азбуку Морзе, морскую флажковую азбуку, систему Брайля для слепых и др. В вычислительной технике также существует своя система кодирования – она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1 (используется двоичная система счисления). Эти знаки называются двоичными цифрами, или битами (binary digital). Если увеличивать на единицу количество разрядов в системе двоичного кодирования, то увеличивается в два раза количество значений, которое может быть выражено в данной системе. Для расчета количества значений используется следующая формула: N=2m, где N – количество независимо кодируемых значений, а m – разрядность двоичного кодирования, принятая в данной системе. Например, какое количество значений (N) можно закодировать 10-ю разрядами (m)? Для этого возводим 2 в 10 степень (m) и получаем N=1024, т. е. в двоичной системе кодирования 10-ю разрядами можно закодировать 1024 независимо кодируемых значения. Кодирование текстовой информации Для кодирования текстовых данных используются специально разработанные таблицы кодировки, основанные на сопоставлении каждого символа алфавита с определенным целым числом. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы. Но не все так просто, и существуют определенные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время, наоборот, вызваны изобилием одновременно действующих и противоречивых стандартов. Практически для всех распространенных на земном шаре языков созданы свои кодовые таблицы. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, что до сих пор пока еще не стало возможным. Кодирование графической информации Кодирование графической информации основано на том, что изображение состоит из мельчайших точек, образующих характерный узор, называемый растром. Каждая точка имеет свои линейные координаты и свойства (яркость), следовательно, их можно выразить с помощью целых чисел – растровое кодирование позволяет использовать двоичный код для представления графической информации. Черно-белые иллюстрации представляются в компьютере в виде комбинаций точек с 256 градациями серого цвета – для кодирования яркости любой точки достаточно восьмиразрядного двоичного числа. Для кодирования цветных графических изображений применяется принцип декомпозиции (разложения) произвольного цвета на основные составляющие. При этом могут использоваться различные методы кодирования цветной графической информации. Например, на практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешивания основных цветов. В качестве таких составляющих используют три основных цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, B). Такая система кодирования называется системой RGB. На кодирование цвета одной точки цветного изображения надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color). Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Соответственно дополнительными цветами являются: голубой (Cyan, C), пурпурный (Magenta, M) и желтый (Yellow, Y). Такой метод кодирования принят в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black, K). Данная система кодирования обозначается CMYK, и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим называется полноцветным (True Color). Если уменьшать количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color. Кодирование звуковой информации Приемы и методы кодирования звуковой информации пришли в вычислительную технику наиболее поздно и до сих пор далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, хотя можно выделить два основных направления. Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармоничных сигналов разной частоты, каждый из которых представляет правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях часть информации теряется, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с «окрасом», характерным для электронной музыки. Метод таблично-волнового синтеза (Wave-Table) лучше соответствует современному уровню развития техники. Имеются заранее подготовленные таблицы, в которых хранятся образцы звуков для множества различных музыкальных инструментов. В технике такие образцы называются сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Читайте также: lektsia.com 6 способов кодирования информации Одна и та же информация может представляться в нескольких формах. Основные способы кодирования позволяют это сделать в современном мире. После появления компьютерных технологий появилась необходимость кодирования любого типа информации, с которыми работает человек. Но решать задачу такого типа начали еще задолго до появления компьютеров. Навигатор по способам  1 способ. Двоичное кодирование. 1 способ. Двоичное кодирование.
Одним из самых популярных и распространенных методов представления информации считается именно двоичное кодирование. В работе с вычислительными машинами, роботами и станками с числовым программным управлением чаще всего кодируют информацию в форме слов двоичного алфавита. 2 способ. Стенография. Этот способ относят к методам кодирования текстовой информации при помощи специальных знаков. Этот способ самый быстрый при записи устной речи. Навыками стенографии владеют только некоторые специально обученные люди, которым и дали название стенографисты. Такие люди успевают записать текст синхронно с речью человека, который выступает. 3 способ. Синхронизация. В процессе работы с цифровой информацией особенное значение получает синхронизация. В момент считывания либо записи информации немаловажным остается точное определение времени каждой смены знака. Если синхронизации нет, то период смены знака может определяться неправильно. В итоге этого неизбежной будет потеря или искажение данных. 4 способ. Run Length Limited — RLL. На сегодняшний день одни из самых популярных методов является кодирование информации с ограничением длины поля записи. Благодаря этому способу на диске можно разместить в полтора раза больше данных, нежели в процессе записи по методу MFM. Используя этот метод происходит кодирование не отдельного бита, а целой группы. 5 способ. Таблицы перекодировки. Таблицей перекодировки считается та, которая содержит перечень кодируемых символов, упорядоченный специальным образом. Соответственно с этим и происходит преобразование символа в его двоичный код и обратно. 6 способ. Матричный способ. Матричный принцип кодирования графических изображений состоит в том, что картинка разбивается на заданное количество столбцов и строк. После этого каждый элемент полученной сетки кодируется по выбранному правилу. Вам рекомендуется обратить внимание Закладка Постоянная ссылка. 10-sposobov.ru Кодирование информации Код — это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий. Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Обычно каждый образ при кодировании (иногда говорят — шифровке) представлении отдельным знаком. Знак - это элемент конечного множества отличных друг от друга элементов. В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (например, звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью программ для компьютера можно выполнить преобразования полученной информации, например "наложить" друг на друга звуки от разных источников. Аналогичным образом на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов. Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере. Способы кодирования информации. Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована. Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита. Кодирование символьной (текстовой) информации. Основная операция, производимая над отдельными символами текста - сравнение символов. При сравнении символов наиболее важными аспектами являются уникальность кода для каждого символа и длина этого кода, а сам выбор принципа кодирования практически не имеет значения. Для кодирования текстов используются различные таблицы перекодировки. Важно, чтобы при кодировании и декодировании одного и того же текста использовалась одна и та же таблица. Таблица перекодировки - таблица, содержащая упорядоченный некоторым образом перечень кодируемых символов, в соответствии с которой происходит преобразование символа в его двоичный код и обратно. Наиболее популярные таблицы перекодировки: ДКОИ-8, ASCII, CP1251, Unicode. Исторически сложилось, что в качестве длины кода для кодирования символов было выбрано 8 бит или 1 байт. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти. Различных комбинаций из 0 и 1 при длине кода 8 бит может быть 28 = 256, поэтому с помощью одной таблицы перекодировки можно закодировать не более 256 символов. При длине кода в 2 байта (16 бит) можно закодировать 65536 символов. Кодирование числовой информации. Сходство в кодировании числовой и текстовой информации состоит в следующем: чтобы можно было сравнивать данные этого типа, у разных чисел (как и у разных символов) должен быть различный код. Основное отличие числовых данных от символьных заключается в том, что над числами кроме операции сравнения производятся разнообразные математические операции: сложение, умножение, извлечение корня, вычисление логарифма и пр. Правила выполнения этих операций в математике подробно разработаны для чисел, представленных в позиционной системе счисления. Основной системой счисления для представления чисел в компьютере является двоичная позиционная система счисления. Кодирование текстовой информации В настоящее время, большая часть пользователей, при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др. Подсчитаем, сколько всего символов и какое количество бит нам нужно. 10 цифр, 12 знаков препинания, 15 знаков арифметических действий, буквы русского и латинского алфавита, ВСЕГО: 155 символов, что соответствует 8 бит информации. Единицы измерения информации. 1 байт = 8 бит 1 Кбайт = 1024 байтам 1 Мбайт = 1024 Кбайтам 1 Гбайт = 1024 Мбайтам 1 Тбайт = 1024 Гбайтам Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255. Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой Основным отображением кодирования символов является код ASCII - American Standard Code for Information Interchange- американский стандартный код обмена информацией, который представляет из себя таблицу 16 на 16, где символы закодированы в шестнадцатеричной системе счисления. Кодирование графической информации. Важным этапом кодирования графического изображения является разбиение его на дискретные элементы (дискретизация). Основными способами представления графики для ее хранения и обработки с помощью компьютера являются растровые и векторные изображения Векторное изображение представляет собой графический объект, состоящий из элементарных геометрических фигур (чаще всего отрезков и дуг). Положение этих элементарных отрезков определяется координатами точек и величиной радиуса. Для каждой линии указывается двоичные коды типа линии (сплошная, пунктирная, штрихпунктирная), толщины и цвета. Растровое изображение представляет собой совокупность точек (пикселей), полученных в результате дискретизации изображения в соответствии с матричным принципом. Матричный принцип кодирования графических изображений заключается в том, что изображение разбивается на заданное количество строк и столбцов. Затем каждый элемент полученной сетки кодируется по выбранному правилу. Pixel (picture element - элемент рисунка) - минимальная единица изображения, цвет и яркость которой можно задать независимо от остального изображения. В соответствии с матричным принципом строятся изображения, выводимые на принтер, отображаемые на экране дисплея, получаемые с помощью сканера. Качество изображения будет тем выше, чем "плотнее" расположены пиксели, то есть чем больше разрешающая способность устройства, и чем точнее закодирован цвет каждого из них. Для черно-белого изображения код цвета каждого пикселя задается одним битом. Если рисунок цветной, то для каждой точки задается двоичный код ее цвета. Поскольку и цвета кодируются в двоичном коде, то если, например, вы хотите использовать 16-цветный рисунок, то для кодирования каждого пикселя вам потребуется 4 бита (16=24), а если есть возможность использовать 16 бит (2 байта) для кодирования цвета одного пикселя, то вы можете передать тогда 216 = 65536 различных цветов. Использование трех байтов (24 битов) для кодирования цвета одной точки позволяет отразить 16777216 (или около 17 миллионов) различных оттенков цвета - так называемый режим “истинного цвета” (True Color). Заметим, что это используемые в настоящее время, но далеко не предельные возможности современных компьютеров. Кодирование звуковой информации. Из курса физики вам известно, что звук - это колебания воздуха. По своей природе звук является непрерывным сигналом. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки аналоговый сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел, а для этого его необходимо дискретизировать и оцифровать. Можно поступить следующим образом: измерять амплитуду сигнала через равные промежутки времени и записывать полученные числовые значения в память компьютера. mirznanii.com Кодирование информации Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернет, создавать и обрабатывать графические изображения, а возможность использования компьютера в сфере компьютерных игр на первый взгляд выглядит совершенно несовместимой с образом суперарифмометра, перемалывающего сотни миллионов цифр в секунду. Составляя информационную модель объекта или явления, мы должны договориться о том, как понимать те или иные обозначения. То есть договориться о виде представления информации. Человек выражает свои мысли в виде предложений, составленных из слов. Они являются алфавитным представлением информации. Основу любого языка составляет алфавит - конечный набор различных знаков (символов) любой природы, из которых складывается сообщение. Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года. Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила - законы записи этих кодов, т.е. уметь кодировать. Код - набор условных обозначений для представления информации. Кодирование - процесс представления информации в виде кода. Для общения друг с другом мы используем код - русский язык. При разговоре этот код передается звуками, при письме - буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам. Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы. Кодирование данных двоичным кодом. По мере развития техники появлялись разные способы кодирования информации. Во второй половине XIXвека американский изобретатель Сэмюэль Морзе изобрел удивительный код, который служит человечеству до сих пор. Информация кодируется тремя символами: длинный сигнал (тире), короткий сигнал (точка), нет сигнала (пауза) - для разделения букв. Своя система существует и в вычислительной технике - она называется двоичным кодированиеми основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называютсядвоичными цифрами, по-английски -binary digit или сокращенноbit(бит). Одним битом могут быть выражены два понятия: 0 или 1 (даилинет, черноеилибелое, истинаилиложьи т.п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия: 00 01 10 11 Тремя битами можно закодировать восемь различных значений: 000 001 010 011 100 101 110 111 Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид: , где N- количество независимых кодируемых значений; m - разрядность двоичного кодирования, принятая в данной системе. | m | N | | 1 | 2 | | 2 | 4 | | 3 | 8 | | 4 | 16 | | ... | ... | | 8 | 256 |
studfiles.net История технических способов кодирования информации — МегаЛекции С появлением технических средств хранения и передачи информации возникли новые идеи и приемы кодирования. Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в 1837 году американцем Сэмюэлем Морзе. Телеграфное сообщение — это последовательность электрических сигналов, передаваемая от одного телеграфного аппарата по проводам к другому телеграфному аппарату. Эти технические обстоятельства привели С.Морзе к идее использования всего двух видов сигналов — короткого и длинного — для кодирования сообщения, передаваемого по линиям телеграфной связи. 
Сэмюэль Финли Бриз Морзе (1791–1872), США Такой способ кодирования получил название азбуки Морзе. В ней каждая буква алфавита кодируется последовательностью коротких сигналов (точек) и длинных сигналов (тире). Буквы отделяются друг от друга паузами — отсутствием сигналов. Самым знаменитым телеграфным сообщением является сигнал бедствия “SOS” (SaveOur Souls — спасите наши души). Вот как он выглядит в коде азбуки Морзе, применяемом к английскому алфавиту: ••• ––– ••• Три точки (буква S), три тире (буква О), три точки (буква S). Две паузы отделяют буквы друг от друга. На рисунке показана азбука Морзе применительно к русскому алфавиту. Специальных знаков препинания не было. Их записывали словами: “тчк” — точка, “зпт” — запятая и т.п. Характерной особенностью азбуки Морзе является переменная длина кода разных букв, поэтому код Морзе называют неравномерным кодом. Буквы, которые встречаются в тексте чаще, имеют более короткий код, чем редкие буквы. Например, код буквы “Е” — одна точка, а код твердого знака состоит из шести знаков. Это сделано для того, чтобы сократить длину всего сообщения. Но из-за переменной длины кода букв возникает проблема отделения букв друг от друга в тексте. Поэтому приходится для разделения использовать паузу (пропуск). Следовательно, телеграфный алфавит Морзе является троичным, т.к. в нем используется три знака: точка, тире, пропуск. 
Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце XIX века. В нем использовалось всего два разных вида сигналов. Не важно, как их назвать: точка и тире, плюс и минус, ноль и единица. Это два отличающихся друг от друга электрических сигнала. Длина кода всех символов одинаковаяи равна пяти. В таком случае не возникает проблемы отделения букв друг от друга: каждая пятерка сигналов — это знак текста. Поэтому пропуск не нужен. 
Жан Морис Эмиль Бодо (1845–1903), Франция
Код Бодо — это первый в истории техники способ двоичного кодирования информации. Благодаря этой идее удалось создать буквопечатающий телеграфный аппарат, имеющий вид пишущей машинки. Нажатие на клавишу с определенной буквой вырабатывает соответствующий пятиимпульсный сигнал, который передается по линии связи. Принимающий аппарат под воздействием этого сигнала печатает ту же букву на бумажной ленте. В современных компьютерах для кодирования текстов также применяется равномерный двоичный код (см. “Системы кодирования текста” 2). Методические рекомендации Тема кодирования информации может быть представлена в учебной программе на всех этапах изучения информатики в школе. В пропедевтическом курсе ученикам чаще предлагаются задачи, не связанные с компьютерным кодированием данных и носящие, в некотором смысле, игровую форму. Например, на основании кодовой таблицы азбуки Морзе можно предлагать как задачи кодирования (закодировать русский текст с помощью азбуки Морзе), так и декодирования (расшифровать текст, закодированный с помощью азбуки Морзе). Выполнение таких заданий можно интерпретировать как работу шифровальщика, предлагая различные несложные ключи шифрования. Например, буквенно-цифровой, заменяя каждую букву ее порядковым номером в алфавите. Кроме того, для полноценного кодирования текста в алфавит следует внести знаки препинания и другие символы. Предложите ученикам придумать способ для отличия строчных букв от прописных. При выполнении таких заданий следует обратить внимание учеников на то, что необходим разделительный символ — пробел, поскольку код оказываетсянеравномерным: какие-то буквы шифруются одной цифрой, какие-то — двумя. Предложите ученикам подумать о том, как можно обойтись без разделения букв в коде. Эти размышления должны привести к идее равномерного кода, в котором каждый символ кодируется двумя десятичными цифрами: А — 01, Б — 02 и т.д. Подборки задач на кодирование и шифрование информации имеются в ряде учебных пособий для школы [4]. В базовом курсе информатики для основной школы тема кодирования в большей степени связывается с темой представления в компьютере различных типов данных: чисел, текстов, изображения, звука (см. “Информационные технологии” 2). В старших классах в содержании общеобразовательного или элективного курса могут быть подробнее затронуты вопросы, связанные с теорией кодирования, разработанной К.Шенноном в рамках теории информации. Здесь существует целый ряд интересных задач, понимание которых требует повышенного уровня математической и программистской подготовки учащихся. Это проблемы экономного кодирования, универсального алгоритма кодирования, кодирования с исправлением ошибок. Подробно многие из этих вопросов раскрываются в учебном пособии “Математические основы информатики” [1]. Обработка информации Обработка информации —процесс планомерного изменения содержания или формы представления информации. Обработка информации производится в соответствии с определенными правилами некоторым субъектом или объектом (например, человеком или автоматическим устройством). Будем его называть исполнителем обработки информации. Исполнитель обработки, взаимодействуя с внешней средой, получает из нее входную информацию, которая подвергается обработке. Результатом обработки являетсявыходная информация, передаваемая внешней среде. Таким образом, внешняя среда выступает в качестве источника входной информации и потребителя выходной информации. Обработка информации происходит по определенным правилам, известным исполнителю. Правила обработки, представляющие собой описание последовательности отдельных шагов обработки, называются алгоритмом обработки информации. Исполнитель обработки должен иметь в своем составе обрабатывающий блок, который назовем процессором, и блок памяти, в котором сохраняются как обрабатываемая информация, так и правила обработки (алгоритм). Все сказанное схематически представлено на рисунке. 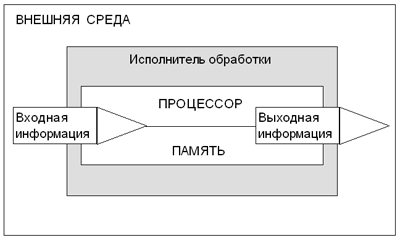
Схема обработки информации Пример.Ученик, решая задачу на уроке, осуществляет обработку информации. Внешней средой для него является обстановка урока. Входной информацией — условие задачи, которое сообщает учитель, ведущий урок. Ученик запоминает условие задачи. Для облегчения запоминания он может использовать записи в тетрадь — внешнюю память. Из объяснения учителя он узнал (запомнил) способ решения задачи. Процессор — это мыслительный аппарат ученика, применяя который для решения задачи, он получает ответ — выходную информацию. Схема, представленная на рисунке, — это общая схема обработки информации, не зависящая от того, кто (или что) является исполнителем обработки: живой организм или техническая система. Именно такая схема реализована техническими средствами в компьютере. Поэтому можно сказать, что компьютер является технической моделью “живой” системы обработки информации. В его состав входят все основные компоненты системы обработки: процессор, память, устройства ввода, устройства вывода (см. “Устройство компьютера” 2). Входная информация, представленная в символьной форме (знаки, буквы, цифры, сигналы), называется входными данными. В результате обработки исполнителем получаются выходные данные. Входные и выходные данные могут представлять собой множество величин — отдельных элементов данных. Если обработка заключается в математических вычислениях, то входные и выходные данные — это множества чисел. На следующем рисунке X: {x1, x2, …, xn} обозначает множество входных данных, а Y: {y1, y2, …, ym} — множество выходных данных: 
Схема обработки данных Обработка заключается в преобразовании множества X в множество Y: P(X)  Y Y Здесь Р обозначает правила обработки, которыми пользуется исполнитель. Если исполнителем обработки информации является человек, то правила обработки, по которым он действует, не всегда формальны и однозначны. Человек часто действует творчески, не формально. Даже одинаковые математические задачи он может решать разными способами. Работа журналиста, ученого, переводчика и других специалистов — это творческая работа с информацией, которая выполняется ими не по формальным правилам. Для обозначения формализованных правил, определяющих последовательность шагов обработки информации, в информатике используется понятие алгоритма (см. “Алгоритм” 2). С понятием алгоритма в математике ассоциируется известный способ вычисления наибольшего общего делителя (НОД) двух натуральных чисел, который называют алгоритм Евклида. В словесной форме его можно описать так: 1. Если два числа равны между собой, то за НОД принять их общее значение, иначе перейти к выполнению пункта 2. 2. Если числа разные, то большее из них заменить на разность большего и меньшего из чисел. Вернуться к выполнению пункта 1. Здесь входными данными являются два натуральных числа — х1 и х2. Результат Y — их наибольший общий делитель. Правило (Р) есть алгоритм Евклида: Алгоритм Евклида (х1, х2) Y Такой формализованный алгоритм легко запрограммировать для современного компьютера. Компьютер является универсальным исполнителем обработки данных. Формализованный алгоритм обработки представляется в виде программы, размещаемой в памяти компьютера. Для компьютера правила обработки (Р) — это программа. Методические рекомендации Объясняя тему “Обработка информации”, следует приводить примеры обработки, как связанные с получением новой информации, так и связанные с изменением формы представления информации. Первый тип обработки: обработка, связанная с получением новой информации, нового содержания знаний. К этому типу обработки относится решение математических задач. К этому же типу обработки информации относится решение различных задач путем применения логических рассуждений. Например, следователь по некоторому набору улик находит преступника; человек, анализируя сложившиеся обстоятельства, принимает решение о своих дальнейших действиях; ученый разгадывает тайну древних рукописей и т.п. Второй тип обработки: обработка, связанная с изменением формы, но не изменяющая содержания. К этому типу обработки информации относится, например, перевод текста с одного языка на другой: изменяется форма, но должно сохраниться содержание. Важным видом обработки для информатики является кодирование.Кодирование — это преобразование информации в символьную форму, удобную для ее хранения, передачи, обработки (см. “Кодирование” 2). Структурирование данных также может быть отнесено ко второму типу обработки. Структурирование связано с внесением определенного порядка, определенной организации в хранилище информации. Расположение данных в алфавитном порядке, группировка по некоторым признакам классификации, использование табличного или графового представления — все это примеры структурирования. Особым видом обработки информации является поиск. Задача поиска обычно формулируется так: имеется некоторое хранилище информации — информационный массив (телефонный справочник, словарь, расписание поездов и пр.), требуется найти в нем нужную информацию, удовлетворяющую определенным условиям поиска(телефон данной организации, перевод данного слова на английский язык, время отправления данного поезда). Алгоритм поиска зависит от способа организации информации. Если информация структурирована, то поиск осуществляется быстрее, его можно оптимизировать (см. “Поиск данных” 2). В пропедевтическом курсе информатики популярны задачи “черного ящика”. Исполнитель обработки рассматривается как “черный ящик”, т.е. система, внутренняя организация и механизм работы которой нам не известен. Задача состоит в том, чтобы угадать правило обработки данных (Р), которое реализует исполнитель. Пример 1. 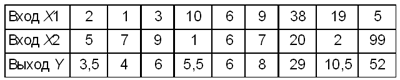
Исполнитель обработки вычисляет среднее значение входных величин: Y = (X1 +X2)/2 Пример 2. 
На входе — слово на русском языке, на выходе — число гласных букв. Наиболее глубокое освоение вопросов обработки информации происходит при изучении алгоритмов работы с величинами и программирования (в основной и старшей школе). Исполнителем обработки информации в таком случае является компьютер, а все возможности по обработке заложены в языке программирования.Программирование есть описание правил обработки входных данных с целью получения выходных данных. Следует предлагать ученикам два типа задач: — прямая задача: составить алгоритм (программу) для решения поставленной задачи; — обратная задача: дан алгоритм, требуется определить результат его выполнения путем трассировки алгоритма. При решении обратной задачи ученик ставит себя в положение исполнителя обработки, шаг за шагом выполняя алгоритм. Результаты выполнения на каждом шаге должны отражаться в трассировочной таблице. Передача информации
megalektsii.ru 6. Кодирование информации Код — система условных знаков (символов) для передачи, обработки и хранения информации (сообщения). Кодирование — процесс представления информации (сообщения) в виде кода. Все множество символов, используемых для кодирования, называется алфавитом кодирования. Например, в памяти компьютера любая информация кодируется с помощью двоичного алфавита, содержащего всего два символа: 0 и 1. Научные основы кодирования были описаны К.Шенноном, который исследовал процессы передачи информации по техническим каналам связи (теория связи, теория кодирования). При таком подходе кодирование понимается в более узком смысле: как переход от представления информации в одной символьной системе к представлению в другой символьной системе. Например, преобразование письменного русского текста в код азбуки Морзе для передачи его по телеграфной связи или радиосвязи. Такое кодирование связано с потребностью приспособить код к используемым техническим средствам работы с информацией . Декодирование — процесс обратного преобразования кода к форме исходной символьной системы, т.е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке. В более широком смысле декодирование — это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение — это декодирование. Цели кодирования и способы кодирования Способ кодирования одного и того же сообщения может быть разным. Например, русский текст мы привыкли записывать с помощью русского алфавита. Но то же самое можно сделать, используя английский алфавит. Иногда так приходится поступать, посылая SMS по мобильному телефону, на котором нет русских букв, или отправляя электронное письмо на русском языке из-за границы, если на компьютере нет русифицированного программного обеспечения. Например, фразу: “Здравствуй, дорогой Саша!” приходится писать так: “Zdravstvui, dorogoi Sasha!”. Существуют и другие способы кодирования речи. Например, стенография — быстрый способ записи устной речи. Ею владеют лишь немногие специально обученные люди — стенографисты. Стенографист успевает записывать текст синхронно с речью говорящего человека. В стенограмме один значок обозначал целое слово или словосочетание. Расшифровать (декодировать) стенограмму может только стенографист. Приведенные примеры иллюстрируют следующее важное правило: для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от ряда обстоятельств: цели кодирования, условий, имеющихся средств. Если надо записать текст в темпе речи — используем стенографию; если надо передать текст за границу — используем английский алфавит; если надо представить текст в виде, понятном для грамотного русского человека, — записываем его по правилам грамматики русского языка. Еще одно важное обстоятельство: выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Покажем это на примере представления чисел — количественной информации. Используя русский алфавит, можно записать число “тридцать пять”. Используя же алфавит арабской десятичной системы счисления, пишем: “35”. Второй способ не только короче первого, но и удобнее для выполнения вычислений. Какая запись удобнее для выполнения расчетов: “тридцать пять умножить на сто двадцать семь” или “35 х 127”? Очевидно — вторая. Однако если важно сохранить число без искажения, то его лучше записать в текстовой форме. Например, в денежных документах часто сумму записывают в текстовой форме: “триста семьдесят пять руб.” вместо “375 руб.”. Во втором случае искажение одной цифры изменит все значение. При использовании текстовой формы даже грамматические ошибки могут не изменить смысла. Например, малограмотный человек написал: “Тристо семдесять пят руб.”. Однако смысл сохранился. В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью. Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука под названием криптография . studfiles.net
|